Dateinamen und Ordnerstruktur in paperless-ngx automatisch vergeben lassen
Für ein papierloses Büro ist das kostenlose Dokumentenmanagement-System paperless-ngx ein extrem hilfreiches Tool. In diesem Artikel gehen wir zunächst darauf ein, wie paperless-ngx mit Dokumenten umgeht, um anschließend anhand eines Beispiels zu zeigen, wie man die archivierten PDF-Dokumente automatisch benennen lassen kann.
Hintergrund: So geht paperless-ngx mit Dokumenten um
Hinter den Kulissen arbeitet paperless mit drei "Töpfen":
- Consume-Ordner (hier auch "scaninput" genannt)
- Originale-Ordner
- Archiv-Ordner
Der Consume-Ordner
Alle Dokumente, die im Consume-Ordner landen, beispielsweise, weil dein Scanner ihn als Ziel eingestellt hat, werden von paperless-ngx verarbeitet. Alternativ kannst du die Dokumente natürlich auch über das Webinterface direkt hochladen. Der Consume-Ordner ist die bessere Wahl für automatisierte Prozesse (wie z.B. einen Scan), wohingegen ich das Webinterface komfortabler finde, wenn ich Dokumente manuell hinzufügen möchte. Am Ende ist es aber Geschmackssache.
Der Originale-Ordner
Hier landen alle Originale, also alle Dokumente in dem Zustand, wie sie von paperless-ngx konsumiert wurden. Speichert dein Netzwerkscanner also beispielsweise ein PDF ohne Texterkennung in dem Consume-Ordner ab, wird dieses Dokument zunächst in den Originale-Ordner kopiert, bevor damit etwas passiert. Auf diese Weise wird sichergestellt, dass keine Dokumente beschädigt werden und alle Originale jederzeit vorhanden sind.
Der Archiv-Ordner
Eine der für mich am wichtigsten Funktionen von paperless-ngx ist die automatische Texterkennung in PDFs. Jedes PDF, das konsumiert wird, durchläuft diese Texterkennung (auch OCR genannt, Optical Character Recognition) und kann anschließend im Volltext durchsucht werden. Da die Originale ja nicht verändert werden sollen, gibt es für die verarbeiteten PDFs einen eigenen Ordner: das Archiv. Hier landen also alle PDFs, nachdem sie von paperless-ngx verarbeitet wurden. Alle Dokumente im Archiv sind also im Volltext durchsuchbar, sodass man auch ohne das Webinterface von paperless-ngx damit arbeiten könnte.Hinweis:
Die Dokumente in den Ordnern Originale und Archiv bitte nur lesend verarbeiten! Umbenennen, verschieben, etc. würde dazu führen, dass paperless-ngx diese nicht mehr findet.
PDFs automatisch benennen lassen
Wer sich nicht nur auf paperless-ngx verlassen möchte, sondern im Falle eines Falles jederzeit seine Dokumente auch in einer sinnvollen Ordnerstruktur und sinnvoll benannt vorliegen haben möchte, der sollte jetzt definitiv weiterlesen. Es ist nämlich möglich, die Dateinamen (und auch die Ordnerstruktur) im Archiv automatisch generieren zu lassen.
Nehmen wir folgendes Beispiel:
Wir wollen folgende Ordnerstruktur und Dateinamen:
Ordnerstruktur
Jahr, in dem das Dokument erstellt wurde (also NICHT, wann es in paperless-ngx importiert wurde).
Beispiel: Ein Brief wurde am 30.11.2023 verfasst und am 01.01.2024 in paperless gescannt. Dieser Brief soll automatisch in den Ordner "2023" einsortiert werden.
Dateinamen
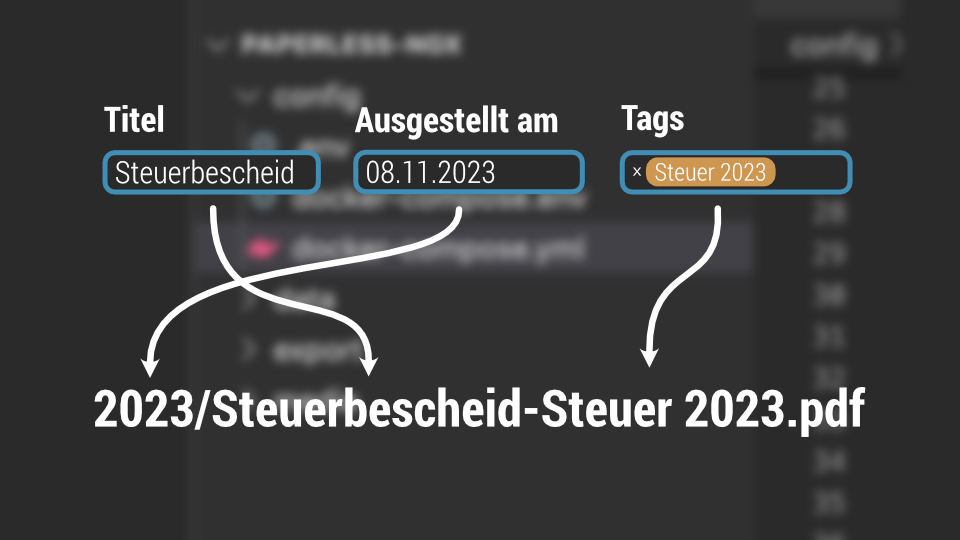
Der Dateiname soll aus dem Titel in paperless-ngx sowie der Liste aller Tags bestehen.
Beispiel:
Titel in paperless-ngx: "Anfrage Finanzamt zu steuerlichen Erfassung"
Tags in paperless-ngx: "Firma", "Steuer 2023"
Resultierender Dateiname
"Anfrage Finanzamt zur steuerlichen Erfassung-Firma,Steuer 2023.pdf" (ja, Leerzeichen im Dateinamen sind nicht ideal, aber ich hatte bisher keine Probleme damit).
Einstellungen in Konfigurations-Datei
Um das umzusetzen, muss man die Konfigurations-Datei entsprechend bearbeiten. Wenn du nach meinen Anleitungen (z.B. in der paperless-ngx Masterclass) vorgegangen bist, befindet sich diese Datei (docker-compose.env) in dem Unterordner paperless-ngx/config/.
Öffne diese Datei (docker-compose.env) mit einem Text-Editor deiner Wahl (ich nutze Visual Studio Code) und ergänze folgende Zeilen:
docker-compose.env
PAPERLESS_FILENAME_FORMAT={created_year}/{title}-{tag_list}
PAPERLESS_FILENAME_FORMAT_REMOVE_NONE=True
Falls die Variable PAPERLESS_FILENAME_FORMAT schon im Dokument vorkommt, ändere nur den rechten Teil hinter dem = ab.
Speichere die Datei und wir können mit dem Anwenden der neuen Einstellungen beginnen.
Anwenden der Änderungen
Leider ist es nicht so, dass paperless-ngx automatisch alle neuen Einstellungen übernimmt und direkt anwendet. Wir müssen das manuell anstoßen, können es aber auch automatisieren (dazu gibt es auch bald einen eigenen Blogbeitrag).
Zunächst müssen wir paperless-ngx neu starten, da wir die docker-compose.env geändert haben.
Dazu gehen wir über SSH in den Ordner, in dem sich die docker-compose.yml befindet, fahren paperless-ngx herunter und starten es anschließend wieder (Eingabe des Passwortes beim zweiten Befehl nötig):
SSH
sudo docker-compose down
sudo docker-compose up -dDurchführung eines Backups
Auch wenn nichts schiefgehen dürfte, empfehle ich immer, vor dem nächsten Schritt ein Backup zu machen. Wie das funktioniert, habe ich in der Masterclass ausführlich erklärt.Automatisches Umbenennen und Verschieben der Archiv-Dokumente
Nun kommt der letzte Schritt: Wir lassen paperless-ngx alle bisherigen Archiv-Dokumente nach dem neuen Schema umbenennen und in die neue Ordnerstruktur verschieben.
SSH
cd /volume1/docker/paperless-ngx/config/
sudo docker-compose exec webserver document_renamer
Das kann nun eine ganze Weile dauern, du erhältst jedoch eine Fortschrittsanzeige im Terminal. Anschließend sind deine Dokumente genau wie beschrieben umbenannt und sortiert im Archiv.
Wo befindet sich das Archiv?
Wenn du nach meinen Anleitungen vorgegangen bist, befindet sich das Archiv auf deinem NAS unter /volume1/docker/paperless-ngx/media/archive/
Viel Erfolg beim Nachbauen!
Diskussion
Du hast Fragen oder Anregungen zu diesem Blog-Beitrag? Stelle sie gerne im Forum. Hier ist der passende Thread dazu: